As the internet and social media wave sweeps across Indonesia, it has increased hate speech incidents. Hate speech is easily spread on social media platforms such as Facebook, Instagram, and Twitter.
Offensive language is most commonly found in posts that tend to be hate-filled. Offensive language can be a word, phrase, or sentence that uses profane language in various contexts, ranging from jokes and criticism to sexual harassment and humiliation.
Endang Wahyu Pamungkas, S.Kom., M.Kom., Ph.D., lecturer in Informatics Engineering at the Faculty of Communication and Informatics, Universitas Muhammadiyah Surakarta (UMS) conducted a literature review research titled “Towards Multi Domain and Multilingual offensive Language Detection: A Survey.” This research discusses the latest developments in the literature, including research on offensive language on various social media platforms.
About the Research
“The literature review we conducted was related to how to detect hate speech. Specifically, we want to investigate challenges related to multidomain and multilingual aspects,” Endang explained.
Through this research, Endang aims to examine the previous studies to detect hate speech on social media, mainly focusing on multidomain and multilingual environments.
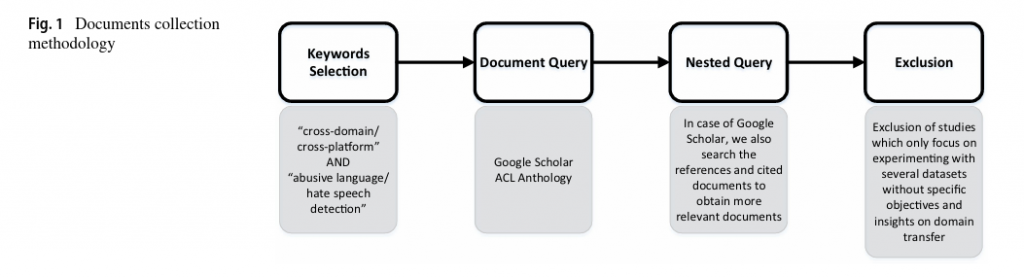
Challenges in Multilingual and Multidomain Detection
“The idea itself is to mimic human intelligence. AI, like humans, has to learn to get smarter. The learning is done through data. The more data it learns from, the better its ability to distinguish hate speech from non-hate speech,” added Dadang, as he is affectionately known.
However, Endang revealed specific challenges in developing AI to detect hate speech. While AI has been shown to perform well in detecting hate speech, most of it tends to focus on a single language.
“If we develop AI in the Indonesian language, then the AI will only be proficient in Indonesian. But if we apply it to other languages, the AI won’t be able to work effectively because the syntax will be different,” Endang continues.
This challenge arises because the use of language in everyday life, especially in Indonesia, is relatively diverse. Endang pointed out that the Indonesian people, who are of different ethnic groups, have other regional languages. This is even more unique when Indonesians use a mixed language on social media, combining regional, national, and foreign languages.
“In Indonesia, it is even more challenging because Indonesians like to have a mix of languages in one social media post,” Endang explains.
As well as being multilingual, Endang revealed that hate speech is categorized as multidomain. According to him, multidomain means hate speech has different contexts or themes.
“Hate speech is a multidomain issue. It can be based on religion, gender, race or politics. So the AI has to be able to detect hate speech within these different domains,” Endang explained.
The Impact of the Research
“As mentioned at the end of the article, exploring datasets, approaches and challenges in a multidomain and multilingual context can help our understanding of this area of research. In addition, it is very important to build unbiased datasets that encompass different offensive language phenomena,” said Endang.
Endang also revealed his main reason for tackling the issue of hate speech. He does not want the next generation exposed to inappropriate words on different platforms.
“Of course, none of us want our children to come across inappropriate words, let alone imitate them. With research in this area, we hope to develop filters or at least become saviours for the next generation to reduce the use of inappropriate words or phrases on social media. Whether we like it or not, we are already living in a digital world,” he explained.
Further Research
“The focus remains the same, namely hate speech using code-mixed language. This is because there are many regional languages. For example, a Javanese person might use a phrase that combines Javanese, Indonesian and sometimes English. That’s just one example, what about Sundanese people, Dayak people, there are many languages in Indonesia,” he explained.
At the end of the interview, he expressed his hope that UMS students and lecturers could contribute and collaborate in the field of research by joining the Center for Social Informatics Studies.
“It would be even better if we collaborate with each other. For instance, in this research, I think Informatics Engineering can collaborate with the Faculty of Psychology, as hate speech also involves the psychological aspect. This also applies to other faculties because we are very open to research collaboration,” concluded Endang.
Writer: Gede Arga Adrian
Editor: Genis Dwi Gustati
Translator: Farizal Luqman Majid